今回は、特許の審査に関する発明を紹介します。特許庁がはじめて取得した特許権です。今日も一緒に勉強しましょう。
従来、特許文献に関する情報を効率よく管理したいという要求があります。
この発明では、例えばAIで学習された学習モデルに基づいて分類情報を生成して検索用データベースに登録します。これにより、自動的に分類情報を生成して登録することができるので、特許に関する情報の管理の効率がよくなります。
特許文献に関する情報を効率よく管理したいという要求
特許の審査のときには、特許文献の検索用データベースが利用されています。特許文献の検索用データベースには、世界の各国で過去に出願された特許文献に関する情報が収められています。
検索用データベースの更新には、膨大な時間が必要とされています。いろいろな国でいろいろなタイミングで発行された文献を登録する必要があるからです。
そのため、特許文献に関する情報を効率よく管理することが求められています。
学習モデルに基づいて分類情報を生成して検索用データベースに登録
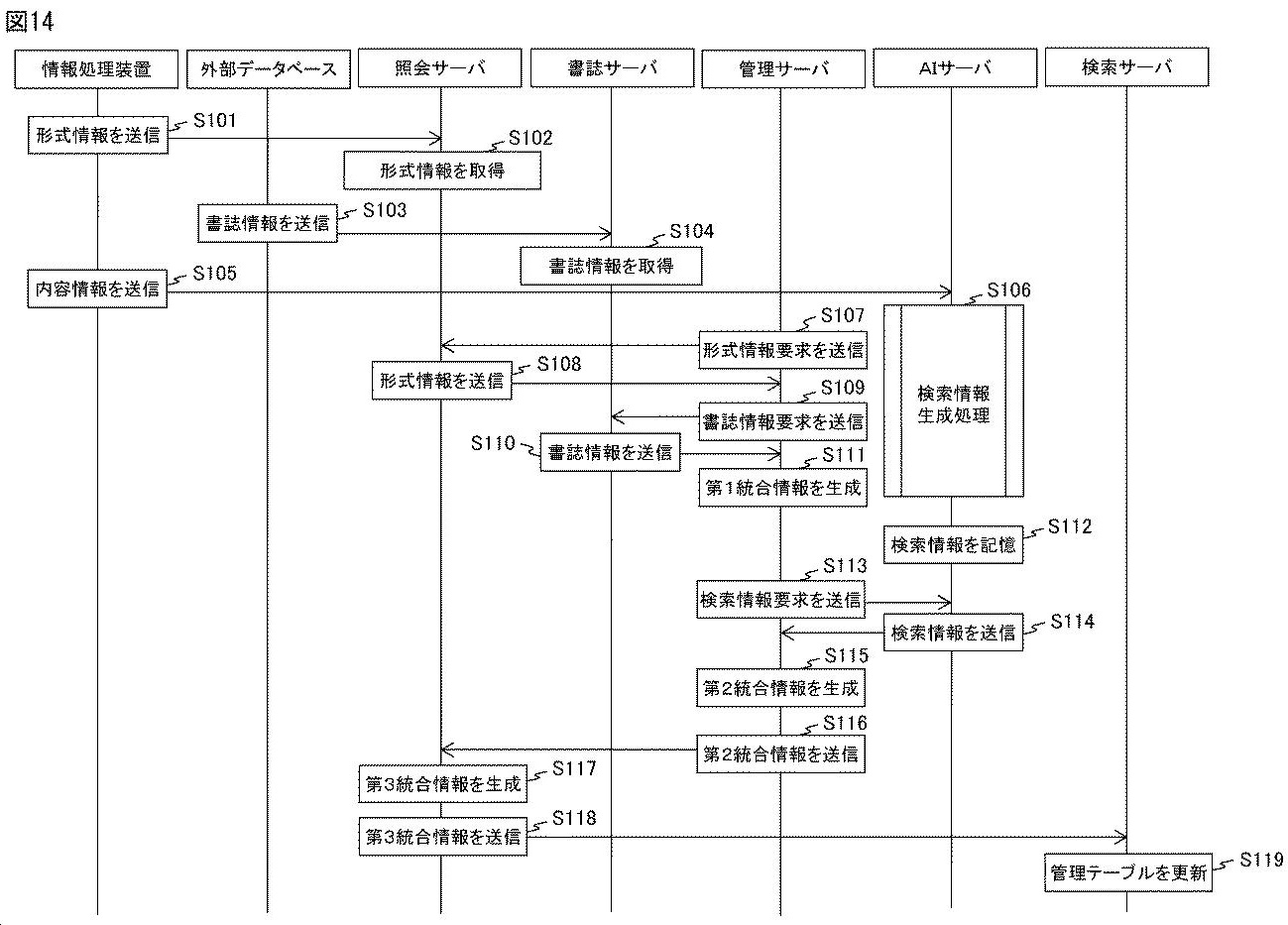
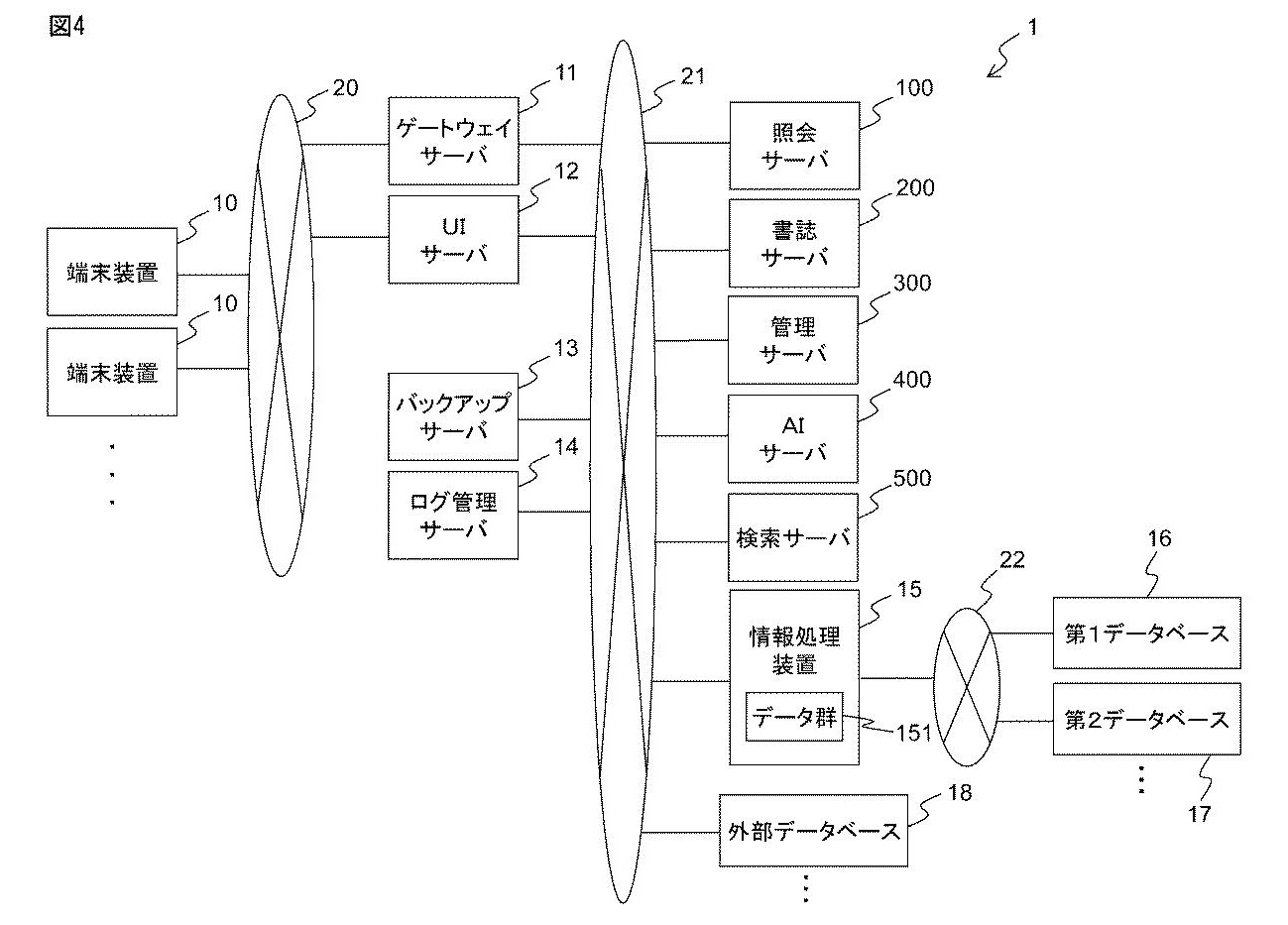
この発明の管理システムは、特許に関する情報を検索用データベースに登録するシステムです。4つのサーバで構成されています
第1サーバは、自国や他国の特許庁のデータベースから特許文献の形式情報を取得します。複数の特許文献は、国ごとにデータ形式が異なっています。
第2サーバは、外部データベースから文献番号と書誌情報とを取得します。外部データベースには、特許文献についての書誌情報が共通のデータ形式で記憶されています。
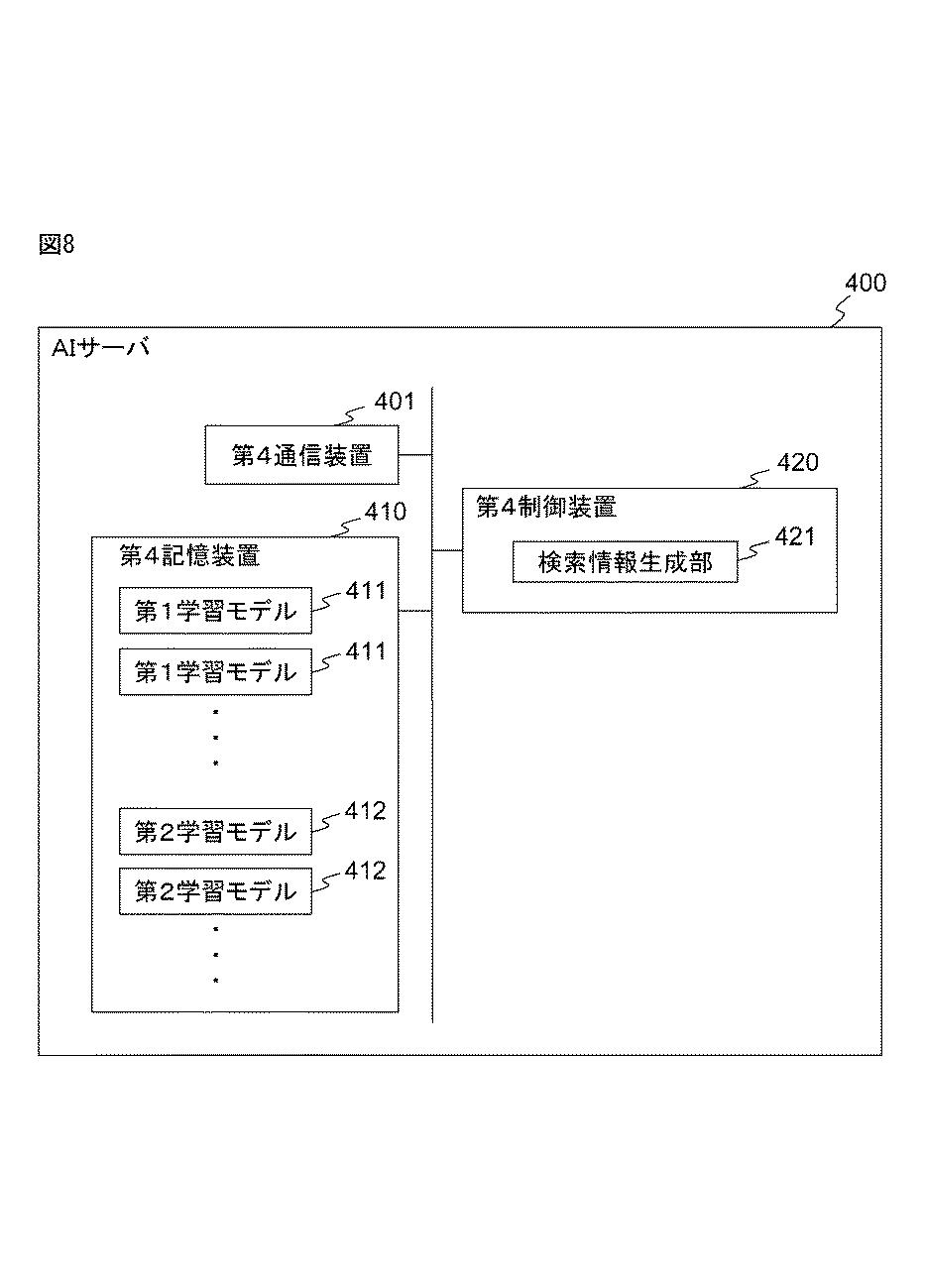
第4サーバは、各特許文献について、その文献の発明の内容(外国語の文献の場合は翻訳文)に基づいて、学習モデルを用いて分類情報を生成します。
第3サーバは、各特許文献の形式情報と書誌情報を統合して第1統合情報を生成します。さらに、第1統合情報と、第4サーバが生成した分類情報とを統合して第2統合情報を生成します。生成した第2統合情報を検索用データベースに登録します。
このようにすることで、自国及び他国の特許文献に関する情報に基づいて学習モデルに基づいて分類情報を生成して検索用データベースに登録することができます。
分類と翻訳エンジンにAIを使用
このシステムでは、分類情報を生成する処理と、翻訳の処理にAIが活用されます。請求項1の「第4サーバ」が、実施形態のAIサーバに対応しています。
まず、分類情報を生成する処理に学習モデルを用いることが請求項1に記載されています。この学習モデルは、例えばAIを用いた学習によって作られます。
分類情報の生成というのは、具体的には、特許の技術分野を示す「テーマコード」から、FIやFタームの情報を生成することです。
AIを用いた学習によって作られているので、この分類情報を生成するための処理をソフトウェアで作ることなく、正確な分類情報を作ることができます。
あと、翻訳エンジンにもAIが活用される例が実施形態に記載されています。
世界中の特許文献を希望する言語で一括検索する「アドパス」
この特許は、実際に特許庁で行っている特許の審査に活用されている「アドパス(ADPAS)」というシステムに関する技術のようです。
特許庁がはじめて取得した特許権ということで注目されています。特許庁からニュースリリースもでています。
特許庁が出しているニュースリリースで特許を取得した目的について説明されています。
(2)国内ユーザーや諸外国の特許庁等に広く安心してこの特許技術を活用頂くこと
このようなシステムを利用して、効率的かつ質の高い特許審査が提供されるとのことで、とてもよいと思います。
特許第6691280号 特許庁
出願日:2020年1月22日 登録日:2020年4月14日
特許文献に関する情報を効率良く管理する。
【請求項1】
複数の特許文献に関する情報を検索用データベースに登録するための管理システムであって、
所定期間に、自国の特許庁及び複数の他国の特許庁が有するデータベースからそれぞれ収集した、国毎にデータ形式が異なる複数の特許文献について、少なくとも文献番号を含み且つ特許文献を一意に識別可能なデータを含む形式情報と、少なくとも各特許文献の発明の内容を含む内容情報とが含まれるデータ群から、各特許文献について、前記形式情報を取得する第1 サーバと、
複数の国の特許庁に出願又は登録された特許文献について、国毎にデータ形式が異なるデータを含む書誌情報が共通のデータ形式に変換されて記憶された外部データベースから、各特許文献について、文献番号と、前記共通のデータ形式に変換された書誌情報とを取得する第2サーバと、
前記第1サーバが前記形式情報を取得した各特許文献について、前記形式情報に含まれる各データを、前記形式情報及び前記書誌情報の各データ項目が所定の順序で並べられた第1テーブルの対応する位置に格納し、当該各特許文献について前記第2サーバが書誌情報を取得している場合は、文献番号をキーとして、当該書誌情報に含まれる各データを前記第1テーブルの対応する位置に格納することにより、前記形式情報及び前記書誌情報を統合した第1統合情報を生成する第3サーバと、
前記データ群から、各特許文献について、文献番号と、前記内容情報とを取得し、前記発明の内容が所定言語で記載された特許文献については当該発明の内容に基づき、前記発明の内容が前記所定言語で記載されていない特許文献については前記発明の内容が前記所定言語で記載された翻訳文に基づいて、学習モデルを用いて、各特許文献の分類情報を生成する第4サーバと、を有し、
前記第3サーバは、前記第1統合情報が完成した後に、前記第1サーバが前記形式情報を取得した特許文献について、文献番号をキーとして、前記第1統合情報に含まれる各データと、前記分類情報に含まれる各データとを、前記第1統合情報及び前記分類情報の各データ項目が所定の順序で並べられた第2テーブルの対応する位置に格納することにより、前記第1統合情報及び前記分類情報を統合した第2統合情報を生成し、前記生成した第2統合情報を検索用データベースに登録する、
ことを特徴とする管理システム。
今日のみどころ
特許庁がはじめて取得した特許権ということで紹介しました。請求項の記載がどんな感じかというのも気になるところでした。
請求項は、たくさん用語をいれて詳しく書かれています。一般的に用語を多くすると技術の限定が多くなって、権利範囲が狭くなるといわれています。そういう意味では、この特許は権利範囲を広くしようという意図があまりなかったのかもしれません。
明細書や図面については、細かいところもしっかり書かれていて充実していると思います。
おそらく、仮に第三者にこのような権利を取得されると特許庁の審査に支障がでてくるので、特許庁自身がこの技術の権利を持っておく必要があるのではないかと思います。
特許庁自身も出願人の立場で特許の出願をするというのがちょっとうれしい感じがしますね。